
인공신경망과 생물신경망
■ 인공신경망
- 기계학습 역사에서 가장 오래된 기계 학습 모델
- 1950년대 퍼셉트론 (인공두뇌학 cybernetics) → 1980년대 다층 퍼셉트론 (결합설 connectionism) →2000년대 깊은 인공신경망 (심층학습 deep learning)
- 현재 다양한 형태의 인공신경망을 가지며, 주목할 만한 결과를 제공함
■ 사람의 뉴런 neuron
- 두뇌의 가장 작은 정보처리 단위
- 구조
- 세포체(cell body)는 간단한 연산
- 수상돌기(dendrite)는 신호 수신
- 축삭(axon)은 처리 결과를 전송
- 사람은 10**11개의 정도의 뉴런을 가지며, 각 뉴런은 약 1000개 다른 뉴런과 연결되어 10**14개 연결을 가짐
■ 두 줄기 연구의 동반상승(synergy) 효과
- 컴퓨터 과학(computer science)
- 컴퓨터의 계산(연산) 능력의 획기적인 발전
- 뇌 (의학) 과학 (neuron science)
- 뇌의 정보처리 방식 규명 연구
→ 컴퓨터가 사람 뇌의 정보처리를 모방하여 지능적 행위를 할 수 있는 인공지능 도전
- 뉴런의 동작 이해를 모방한 초기 인공 신경망(artificial neural networks(ANN)) 연구 시작
→ 퍼셉트론 고안
■ 사람의 신경망과 인공신경망 비교
| 사람 신경망 | 인공 신경망 |
| 세포체 | 노드 |
| 수상돌기 | 입력 |
| 축삭 | 출력 |
| 시냅스 | 가중치 |
신경망의 종류
■ 인공신경망은 다양한 모델이 존재함
- 전방(forward) 신경망과 순환(recurrent) 신경망
- 얕은(shallow) 신경망과 깊은(deep) 신경망

■ 결정론(deterministic) 신경망과 확률론적(stochastic) 신경망 비교
- 결정론 신경망
- 모델의 매개변수와 조건에 의해 출력이 완전히 결정되는 신경망
- 확률론적 신경망
- 고유의 임의성을 가지고, 매개변수와 조선이 같더라도 다른 출력을 가지는 신경망
퍼셉트론
■ 구조: 절(node), 가중치(weight), 층(layer)과 같은 새로운 개념의 구조 도입
■ 제시된 퍼셉트론 구조의 학습 알고리즘을 제안
■ 원시적 신경망이지만, 깊은 인공신경마을 포함한 현대 인공신경망의 토대
- 깊은 인공신경망은 퍼셉트론의 병렬 배치를 순차적으로 구족로 결합함
→ 현대 인공신경망의 중요한 구성 요소가 됨
■ 퍼셉트론의 구조
- 입력
- i번째 노드는 특징 벡터 x = (x1, x2, ..., xd)**T의 요소 xi를 담당
- 항상 1이 입력되는 편향(bias) 노드 포함
- 입력과 출력 사이에 연산하는 구조를 가짐
- i번째 입력 노드와 출력 노드를 연결하는 변(edge)는 가중치 wi를 가짐
- 퍼셉트론은 단일 층 구조라고 간주함
- 출력
- 한 개의 노드에 의해 수치(+1 혹은 -1) 출력
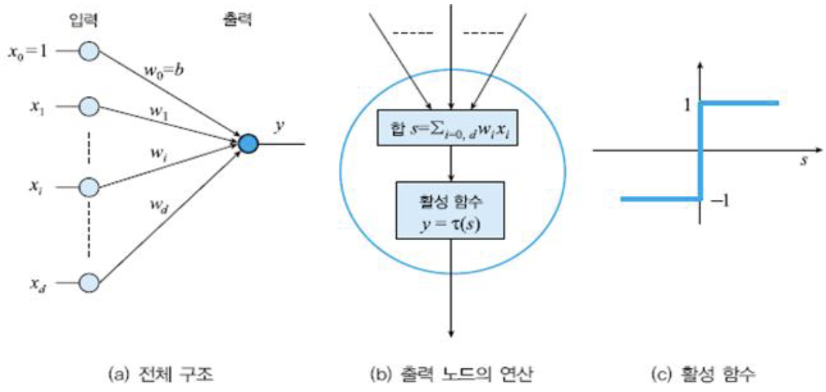
■ 퍼셉트론의 동작
- 선형 연산 → 비선형 연산
- [선형] 입력(특징)값과 가중치를 곱하고, 모두 더해 s를 구함
- [비선형] 활성함수 T를 적용
- 활성함수 T로 계단 함수(step function)를 사용 → 출력 y =+ 1 또는 y =- 1
- 수식
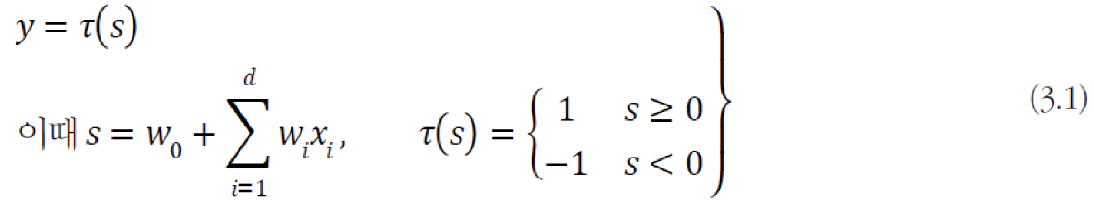
■ 행렬 표기(matrix vector notaion)

- 결정 직선 d(x) = d(x1, x2) = w1x1 + w2x2 + w0 = 0 → x1 + x2 - 0.5 = 0
- w1과 w2는 직선의 기울기, w0은 절편(intercept(편향))을 결정
- 결정 직선은 특징 공간을 +1과 -1의 두 부분공간으로 이 분할하는 분류기 역할
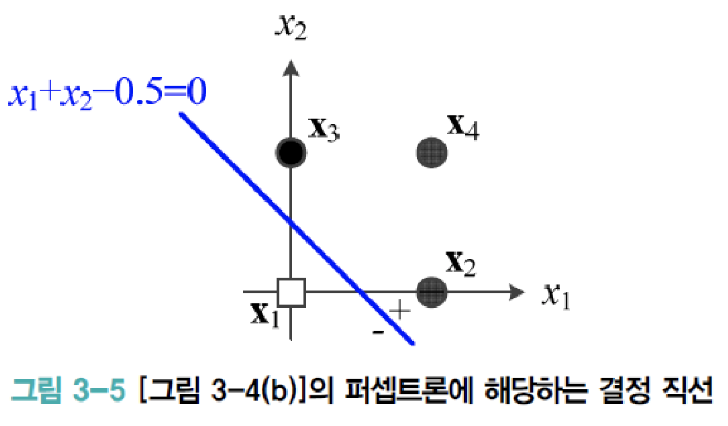
- d차원 공간으로 일반화 d(x) = w1x1 + w2x2 + ... + wdxd + w0 = 0
- 2차원: 결정 직선(decision line), 3차원: 결정 평면(decision plane), 4차원 이상: 결정 초평면(decision hyperplane)
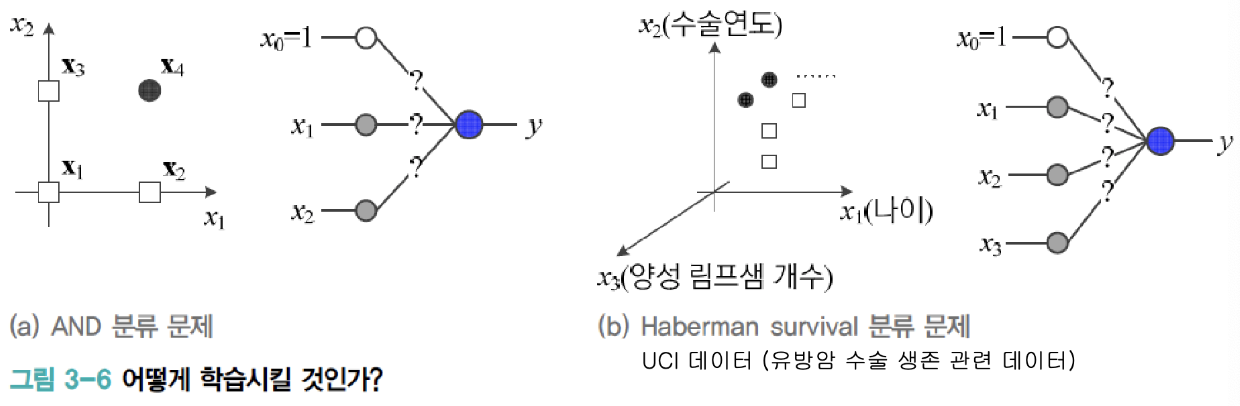
■ 퍼셉트론의 학습
- 지금까지 학습을 마친 퍼셉트론의 동작을 설명
- 학습 문제
- w0, w1, w2이 어떤 값을 가져야 100% 옳게 분류할까?
- 그림은 2차원 공간에 4개 샘플이 있는 훈련집합
- 현실은 d차원 공간에 수백~수만 개의 샘플이 존재 (예, MNIST는 784차원에 6만 개 샘플)
PT-TF 기본연산 (실습)
PyTorch란?
Python 기반의 과학 연산 패키지로 다음과 같은 두 집단을 대상으로 합니다:
- NumPy를 대체하면서 GPU를 이용한 연산이 필요한 경우
- 최대한의 유연성과 속도를 제공하는 딥러닝 연구 플랫폼이 필요한 경우
Tensor는 NumPy의 ndarray와 유사하며, 추가로 GPU를 사용한 연산 가속도 가능합니다.
from __future__ import print_function
import torch
torch.__version__1.7.0+cu101
초기화되지 않은 5x3 행렬을 생성
x = torch.empty(5, 3)
print(x)tensor([[3.2140e-36, 0.0000e+00, 3.3631e-44],
[0.0000e+00, nan, 6.4460e-44],
[1.1578e+27, 1.1362e+30, 7.1547e+22],
[4.5828e+30, 1.2121e+04, 7.1846e+22],
[9.2198e-39, 7.0374e+22, 1.1553e-36]])
무작위로 초기화된 행렬을 생성
x = torch.randn(5, 3)
print(x)
x = torch.rand(5, 3)
print(x)tensor([[ 0.4998, -0.0123, 1.2065],
[ 0.4659, -1.1119, -1.0469],
[ 0.3311, 0.5770, -0.9808],
[-1.6933, -0.4311, 1.7591],
[ 0.3346, 0.6398, -0.9855]])
tensor([[0.4225, 0.6696, 0.4458],
[0.5661, 0.1570, 0.6661],
[0.9700, 0.3892, 0.5740],
[0.8643, 0.8190, 0.6379],
[0.4663, 0.0164, 0.3621]])
dtype이 long이고, 0으로 채워진 행렬을 생성
x = torch.zeros(5, 3, dtype=torch.long)
print(x)tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
x = torch.ones(5, 3, dtype=torch.long)
print(x)tensor([[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]])
다층 퍼셉트론
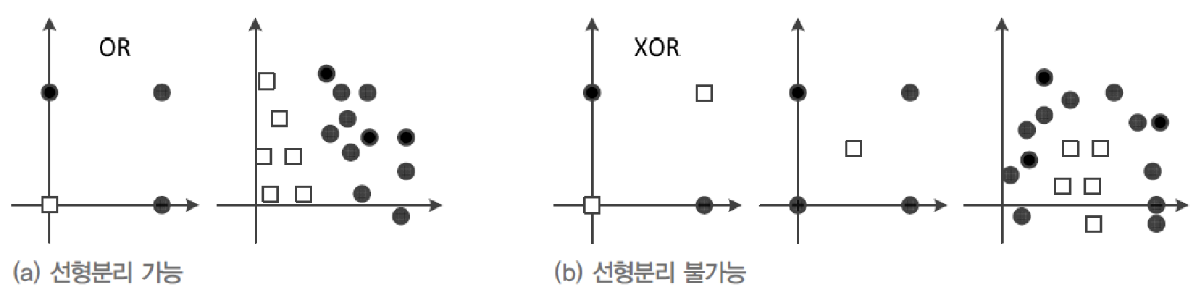
■ 퍼셉트론: 선형 분류기(linear classifier) 한계
- 선형 분리 불가능한 상황에서 일정한 양의 오류
- 예) XOR 문제에서 75% 정확도 한계
- 1969년 Minsky와 Papert의 「Perceptrons」
- 퍼셉트론의 한계를 지적하고, 다층 구조를 이용한 극복 방안을 제시했지만 당시 기술로 불가능
- 1974년 Werbos는 오류 역전파(error backpropagation) 알고리즘의 신경망 활용 가능성 확인
- 1986년 Rumelhart, Hinton의 「Parallel Distributed Processing」
- 다층 퍼셉트론 이론 정립하고, 신경망 재부활
■ 다층 퍼셉트론의 핵심 아이디어
- 은닉층을 둡니다. 은닉층은 원래 특징 공간을 분류햐는데 훨씬 유리한 새로운 특징 공간으로 변환합니다.
- 시그모이드 활성함수를 도입합니다. 퍼셉트론은 계단함수를 활성함수로 사용했으며, 이 함수는 경성 의사결정에 해당합니다. 그러나, 다층 퍼셉트론은 연성 의사결정이 가능한 시그모이드함수를 활성함수로 사용합니다. 연성에서는 출력이 연속값인데, 출력을 신뢰도로 간주함으로 더 융통성 있게 의사결정을 할 수 있습니다.
- 오류 역전파 알고리즘을 사용합니다. 다층 퍼셉트론은 여러 층이 순차적으로 이어진 구조로 역방향을 진행하면서 한번에 한 층씩 그레이디언트를 계산하고, 가중치를 갱신하는 방식의 오류 역전파 알고리즘을 사용합니다.
■ 퍼셉트론 2개를 병렬 결합
- 원래 공간 x = (x1, x2)**T를 새로운 특징 공간 z = (z1,z2)**T로 변환
→ 새로운 특징 공간 z에서 선형 분리 가능함
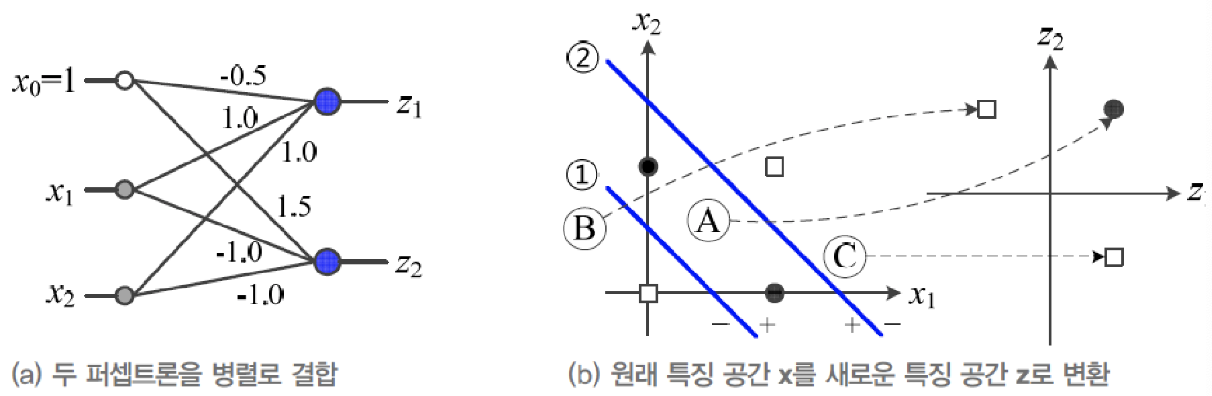
- 사람이 수작업 특징 학습(hand-craft features learning)을 수행한 것과 유사함
■ 추가 퍼셉트론 1개를 순차 결합
- 새로운 특징 공간 z을 선형 분리를 수행하는 퍼셉트론을 순차 결합

■ 다층 퍼셉트론의 용량(capacity)
- 3개 퍼셉트론을 결합한 경우
- 2차원 공간을 7개 영역으로 나누고, 각 영역을 3차원 점으로 변환
- 계단함수를 활성함수 T로 사용을 가정하였으므로 영역을 점으로 변환

- 일반화하여, p개 퍼셉트론을 결합하면 p차원 공간으로 변환
■ 일반적으로 은닉층에서 logistic sigmoid를 활성 함수로 많이 사용
- S자 모양의 넓은 포화곡선은 경사도 기반한 학습(오류 역전파)을 어렵게 함
→ 깊은 신경망에서 ReLU 활용

- 범용적 근사 이론(universal approximation theorem)
- 하나의 은닉층은 함수의 근사를 표현
→ 다층 퍼셉트론도 공간을 변환하는 근사 함수
- 얕은 은닉층의 구조
- 지수적으로 더 넓은 폭(width)이 필요
- 더 과잉적합 되기 쉬움
→ 일반적으로 깊은 은닉층의 구조가 좋은 성능을 가짐

■ 순수한 최적화 알고리즘으로는 높은 성능 불가능
- 데이터 희소성, 잡음, 미숙한 신경망 구조
- 성능 향상을 위한 다양한 경험(heuristics)을 개발하고, 공유
→ 예) 「Neural Networks: Tricks of the Trade」 [2012]
■ 신경망의 경험적 개발에서 중요 쟁점
- 아키텍처: 은닉층과 은닉 노드의 개수를 정해야 합니다. 은닉충과 은닉 노드를 늘리면 신경망의 용량은 커지는 대신, 추정할 매개변수가 많아지고, 학습 과정에서 과잉적합할 가능성이 커집니다. 현대 기계 학습은 복잡한 모델을 사용하되, 적절한 규제 기법을 적용하는 경향이 있습니다.
- 초깃값: 난수를 생성하여 설정하는데, 값의 범위와 분포가 중요합니다.
- 학습률: 처음부터 끝까지 같은 학습률을 사용하는 방식과 처음에는 큰 값으로 시작하고, 점점 줄이는 적응적 방식이 있습니다.
- 활성함수: 초창기 다층 퍼셉트론은 주로 로지스틱 시그모이드나 tanh 함수를 사용했는데, 은닉층의 개수를 늘림에 따라 그레이디언트 소멸과 같은 몇 가지 문제가 발생합니다. 깊은 신경망은 주로 ReLU 함수를 사용합니다.
Pytorch Tutoral - Autograd & MLP(Multi-layer perceptron)
Autograd
- autograd패키지는 텐서의 모든 연산에 대한 자동 미분을 제공
- 실행-기반-정의(define-by-run) 프레임워크로, 코드를 어떻게 작성하여 실행하느냐에 따라 역전파가 정의된다는 것을 의미
Tensor
- torch.Tensor 클래스의 .requires_grad 속성을 True로 설정하면, 해당 텐서에서 이루어진 모든 연산을 추적(track)하기 시작
- 계산이 완료된 후. backward()를 호출하여 모든 변화도(gradient)를 자동으로 계산할 수 있으며 이 Tensor의 변화도는. grad속성에 누적됨
- Tensor가 기록을 추적하는 것을 중단하게 하려면,. detach()를 호출하여 연산기록으로부터 분리하여 연산이 추적되는 것을 방지할 수 있음
- 기록을 추적하는 것(과 메모리를 사용하는 것)을 방지하기 위해서 코드 블록을with torch.no_grad():로 감쌀 수 있음
- 이는 변화도(gradient)는 필요 없지만 requires_grad=True가 설정되어 학습 가능한 매개변수를 갖는 모델을 평가(evaluate)할 때 유용
import torch
print(torch.__version__)1.7.0+cu101
# x의 연산 과적을 추적하기 위해 requires_grad=True로 설정
x = torch.ones(2, 2, requires_grad=True)
print(x)
# 직접 생선한 Tensor이기 때문에 grad_fn이 None인 것을 확인할 수 있음
print(x.grad_fn)tensor([[1., 1.], [1., 1.]], requires_grad=True)
None
# y는 연산의 결과로 생성된 것이기 때문에 grad_fn을 갖고 있는 것을 확인 가능
y = x + 2
print(y)tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
# 연산의 결과로 생성된 것이기 때문에 grad_fn을 갖는 것을 확인 가능
print(y.grad_fn)<AddBackward0 object at 0x7 efe58 ead828>
z = y * y * 3
out = z.mean()
# 각각 사용한 func에 맞게 grad_fn이 생성된 것을 확인할 수 있음
print(z)
print(out)tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward0>)
tensor(27., grad_fn=<MeanBackward0>)
- requires_grad_()를 사용하면 기존 Tensor의 requires_grad 값을 바꿀 수 있음
- 입력 값이 지정되지 않으면 기본 값은 False
a = torch.randn(2, 2)
print(a)tensor([[-0.7437, -0.3589],
[-2.0437, -2.0806]])
a = ((a * 3) / (a - 1))
print(a)
print(a.requires_grad)tensor([[1.2795, 0.7924],
[2.0144, 2.0262]])
False
a.requires_grad_(True)tensor([[1.2795, 0.7924],
[2.0144, 2.0262]], requires_grad=True)
print(a.requires_grad)True
b = (a * a).sum()
print(b)
print(b.requires_grad)tensor(10.4281, grad_fn=<SumBackward0>)
True
'BOOTCAMP > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
| [12주차] SQL과 데이터분석 (0) | 2023.06.27 |
|---|---|
| [11주차] CNN & RNN (0) | 2023.06.27 |
| [9주차] ML_basics - Linear Regression (0) | 2023.06.23 |
| [8주차 - Day3] 케글 경진대회 - Spaceship Titanic (0) | 2023.06.23 |
| [8주차 - Day2] monthly project2 (0) | 2023.06.22 |



