
◼ 컴퓨터 비전(CV)의 어려운 점
▪ 관점의 변화: 동일한 객체라도 영상을 찍는 카메라의 이동에 따라 모든 픽셀값이 변화
▪ 경계색 (보호색)으로 배경과 구분이 어려운 경우
▪ 조명에 따른 변화
▪ 기형적인 형태의 영상 존재
▪ 일부가 가려진 영상 존재
▪ 같은 종류 간의 변화가 큼
◼ DMLP와 CNN의 비교
▪ DMLP
• 완전 연결 fully connection 구조로 높은 복잡도
• 학습이 매우 느리고 과잉적합 우려
▪ CNN
• 컨볼루션 연산을 이용한 부분연결 (희소 연결) 구조로 복잡도 크게 낮춤
• 컨볼루션 연산은 좋은 특징 추출
◼ CNN 특징
▪ 격자grid 구조 (영상, 음성 등)를 갖는 데이터에 적합
▪ 수용장receptive field은 인간시각과 유사
▪ 가변 크기의 입력 처리 가능
◼ 컨볼루션 (합성곱) convolution 연산
▪ 컨볼루션은 해당하는 요소끼리 곱하고 결과를 모두 더하는 선형 연산
▪ 식 (4.10)과 식 (4.11)에서 u는 커널 kernel (혹은 필터 filter), z는 입력, s는 출력 (특징 맵 feature map)
• 영상에서 특징을 추출하기 위한 용도로 사용됨 (=공간 필터spatial filtering)
◼ 빌딩 블록building block
▪ CNN은 빌딩 블록을 이어 붙여 깊은 구조로 확장
▪ 컨볼루션층 → 활성함수 (주로 ReLU 사용) → 풀링층
▪ 다중 커널을 사용하여 다중 특징 맵을 추출함
GoogleNet
모델 블록
import torch
from torch import Tensor
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.optim import lr_scheduler
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
from typing import Optional, Tuple, List, Callable, Any
import time
import os
import copy
from collections import namedtuple__all__ = ['GoogLeNet', 'googlenet', "GoogLeNetOutputs", "_GoogLeNetOutputs"]
model_urls = {
# GoogLeNet ported from TensorFlow
'googlenet': 'https://download.pytorch.org/models/googlenet-1378be20.pth',
}
GoogLeNetOutputs = namedtuple('GoogLeNetOutputs', ['logits', 'aux_logits2', 'aux_logits1'])
GoogLeNetOutputs.__annotations__ = {'logits': Tensor, 'aux_logits2': Optional[Tensor],
'aux_logits1': Optional[Tensor]}
# Script annotations failed with _GoogleNetOutputs = namedtuple ...
# _GoogLeNetOutputs set here for backwards compat
_GoogLeNetOutputs = GoogLeNetOutputs
def googlenet(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> "GoogLeNet":
r"""GoogLeNet (Inception v1) model architecture from
`"Going Deeper with Convolutions" `_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
aux_logits (bool): If True, adds two auxiliary branches that can improve training.
Default: *False* when pretrained is True otherwise *True*
transform_input (bool): If True, preprocesses the input according to the method with which it
was trained on ImageNet. Default: *False*
"""
if pretrained:
if 'transform_input' not in kwargs:
kwargs['transform_input'] = True
if 'aux_logits' not in kwargs:
kwargs['aux_logits'] = False
if kwargs['aux_logits']:
warnings.warn('auxiliary heads in the pretrained googlenet model are NOT pretrained, '
'so make sure to train them')
original_aux_logits = kwargs['aux_logits']
kwargs['aux_logits'] = True
kwargs['init_weights'] = False
model = GoogLeNet(**kwargs)
state_dict = load_state_dict_from_url(model_urls['googlenet'],
progress=progress)
model.load_state_dict(state_dict)
if not original_aux_logits:
model.aux_logits = False
model.aux1 = None # type: ignore[assignment]
model.aux2 = None # type: ignore[assignment]
return model
return GoogLeNet(**kwargs)Conv2d 블록
class BasicConv2d(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
**kwargs: Any
) -> None:
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)Inception 모듈
# Inception Module
class Inception(nn.Module):
def __init__(
self,
in_channels: int,
ch1x1: int,
ch3x3red: int,
ch3x3: int,
ch5x5red: int,
ch5x5: int,
pool_proj: int,
conv_block: Optional[Callable[..., nn.Module]] = None
) -> None:
super(Inception, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1 = conv_block(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
conv_block(in_channels, ch3x3red, kernel_size=1),
conv_block(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
conv_block(in_channels, ch5x5red, kernel_size=1),
# Here, kernel_size=3 instead of kernel_size=5 is a known bug.
# Please see https://github.com/pytorch/vision/issues/906 for details.
conv_block(ch5x5red, ch5x5, kernel_size=3, padding=1)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),
conv_block(in_channels, pool_proj, kernel_size=1)
)
def _forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
print('size of brach1', torch.tensor(branch1).shape)
print('size of branch2', torch.tensor(branch2).shape)
print('size of branch3', torch.tensor(branch3).shape)
print('size of branch4', torch.tensor(branch4).shape)
outputs = [branch1, branch2, branch3, branch4]
return outputs
# N * ch * (H * W)
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)Auxiliary Classifier(보조 분류기)
# Auxiliary classifier
class InceptionAux(nn.Module):
def __init__(
self,
in_channels: int,
num_classes: int,
conv_block: Optional[Callable[..., nn.Module]] = None
) -> None:
super(InceptionAux, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.conv = conv_block(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = F.adaptive_avg_pool2d(x, (4, 4))
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
# N x 1024
x = F.dropout(x, 0.7, training=self.training)
# N x 1024
x = self.fc2(x)
# N x 1000 (num_classes)
return xGoogleNet
class GoogLeNet(nn.Module):
__constants__ = ['aux_logits', 'transform_input']
def __init__(
self,
num_classes: int = 1000,
aux_logits: bool = True,
transform_input: bool = False,
init_weights: Optional[bool] = None,
blocks: Optional[List[Callable[..., nn.Module]]] = None
) -> None:
super(GoogLeNet, self).__init__()
if blocks is None:
blocks = [BasicConv2d, Inception, InceptionAux]
if init_weights is None:
# warnings.warn('The default weight initialization of GoogleNet will be changed in future releases of '
# 'torchvision. If you wish to keep the old behavior (which leads to long initialization times'
# ' due to scipy/scipy#11299), please set init_weights=True.', FutureWarning)
init_weights = True
assert len(blocks) == 3
conv_block = blocks[0]
inception_block = blocks[1]
inception_aux_block = blocks[2]
self.aux_logits = aux_logits
self.transform_input = transform_input
self.conv1 = conv_block(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = conv_block(64, 64, kernel_size=1)
self.conv3 = conv_block(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = inception_block(192, 64, 96, 128, 16, 32, 32)
self.inception3b = inception_block(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = inception_block(480, 192, 96, 208, 16, 48, 64)
self.inception4b = inception_block(512, 160, 112, 224, 24, 64, 64)
self.inception4c = inception_block(512, 128, 128, 256, 24, 64, 64)
self.inception4d = inception_block(512, 112, 144, 288, 32, 64, 64)
self.inception4e = inception_block(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.inception5a = inception_block(832, 256, 160, 320, 32, 128, 128)
self.inception5b = inception_block(832, 384, 192, 384, 48, 128, 128)
if aux_logits:
self.aux1 = inception_aux_block(512, num_classes)
self.aux2 = inception_aux_block(528, num_classes)
else:
self.aux1 = None # type: ignore[assignment]
self.aux2 = None # type: ignore[assignment]
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.2)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
import scipy.stats as stats
X = stats.truncnorm(-2, 2, scale=0.01)
values = torch.as_tensor(X.rvs(m.weight.numel()), dtype=m.weight.dtype)
values = values.view(m.weight.size())
with torch.no_grad():
m.weight.copy_(values)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _transform_input(self, x):
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1)
return x
def _forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
print('shape after inception3a', x.shape)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
aux1 = torch.jit.annotate(Optional[torch.Tensor], None)
if self.aux1 is not None:
if self.training:
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
aux2 = torch.jit.annotate(Optional[torch.Tensor], None)
if self.aux2 is not None:
if self.training:
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
return x, aux2, aux1
@torch.jit.unused
def eager_outputs(self, x, aux2, aux1):
if self.training and self.aux_logits:
return _GoogLeNetOutputs(x, aux2, aux1)
else:
return x # type: ignore[return-value]
def forward(self, x):
x = self._transform_input(x)
x, aux1, aux2 = self._forward(x)
aux_defined = self.training and self.aux_logits
if torch.jit.is_scripting():
if not aux_defined:
warnings.warn("Scripted GoogleNet always returns GoogleNetOutputs Tuple")
return GoogLeNetOutputs(x, aux2, aux1)
else:
return self.eager_outputs(x, aux2, aux1)모델 형태
ex_net = GoogLeNet()
ex_netGoogLeNet(
(conv1): BasicConv2 d(
(conv): Conv2 d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn): BatchNorm2 d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True))
.
.
.
(avgpool): AdaptiveAvgPool2 d(output_size=(1, 1))
(dropout): Dropout(p=0.2, inplace=False)
(fc): Linear(in_features=1024, out_features=1000, bias=True)
)
from torchvision import datasets, models, transforms
# CIFAR-10 dataset
transform = transforms.Compose([
transforms.Pad(4),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor()])
train_dataset = torchvision.datasets.CIFAR10(root='../../data/',
train=True,
transform=transform,
download=True)
test_dataset = torchvision.datasets.CIFAR10(root='../../data/',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=100,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=100,
shuffle=False)dataiter = iter(train_loader)
images, labels = dataiter.next()
output = ex_net(images)
outputsize of brach1 torch.Size([100, 64, 4, 4])
size of branch2 torch.Size([100, 128, 4, 4])
size of branch3 torch.Size([100, 32, 4, 4])
.
.
.
size of branch2 torch.Size([100, 384, 1, 1]) size of branch3 torch.Size([100, 128, 1, 1]) size of branch4 torch.Size([100, 128, 1, 1])
GoogLeNetOutputs(logits=tensor([[ 0.1154, 0.1125, 0.3554,..., -0.1510, -0.1992, -0.0225],
[ 0.0099, 0.4095, 0.1099,..., -0.4636, -0.0611, 0.3803],
[ 0.0371, 0.1296, 0.1010,..., -0.1527, -0.1412, 0.0798],...,
.
.
.
[ 0.0449, 0.0673, -0.1286,..., 0.0264, -0.1612, -0.0791]], grad_fn=<AddmmBackward>))
Pretrained 모델을 사용한 학습
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
model = torch.hub.load('pytorch/vision:v0.6.0', 'googlenet', pretrained=True)
print(model)HBox(children=(FloatProgress(value=0.0, max=52147035.0), HTML(value='')))
GoogLeNet(
(conv1): BasicConv2 d(
(conv): Conv2 d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
.
.
.
)
(aux1): None
(aux2): None
(avgpool): AdaptiveAvgPool2 d(output_size=(1, 1))
(dropout): Dropout(p=0.2, inplace=False)
(fc): Linear(in_features=1024, out_features=1000, bias=True)
)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10)
model = model.to(device)cuda
num_epochs = 80
learning_rate = 0.001
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
transform = transforms.Compose([
transforms.Pad(4),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor()])# CIFAR-10 dataset
train_dataset = torchvision.datasets.CIFAR10(root='../../data/',
train=True,
transform=transform,
download=True)
test_dataset = torchvision.datasets.CIFAR10(root='../../data/',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=100,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=100,
shuffle=False)def train_model(model, criterion, dataloaders, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 각 에폭(epoch)은 학습 단계와 검증 단계를 갖습니다.
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 모델을 학습 모드로 설정
else:
model.eval() # 모델을 평가 모드로 설정
running_loss = 0.0
running_corrects = 0
# 데이터를 반복
for inputs, labels in dataloaders:
inputs = inputs.to(device)
labels = labels.to(device)
# 매개변수 경사도를 0으로 설정
optimizer.zero_grad()
# 순전파
# 학습 시에만 연산 기록을 추적
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 학습 단계인 경우 역전파 + 최적화
if phase == 'train':
loss.backward()
optimizer.step()
# 통계
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / len(dataloaders)
epoch_acc = running_corrects.double() / len(dataloaders)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# 모델을 깊은 복사(deep copy)함
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 가장 나은 모델 가중치를 불러옴
model.load_state_dict(best_model_wts)
return modelmodel_ft = train_model(model, criterion, train_loader, optimizer, exp_lr_scheduler,
num_epochs=25)Epoch 0/24
----------
train Loss: 170.5447 Acc: 39.4380
val Loss: 124.1767 Acc: 55.9340
.
.
.
Epoch 24/24
----------
train Loss: 68.5837 Acc: 75.9620
val Loss: 62.6932 Acc: 78.0160
Training complete in 19m 11s
Best val Acc: 78.182000
모델 검증
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model_ft(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the model on the test images: {} %'.format(100 * correct / total))Accuracy of the model on the test images: 76.65 %
ResNet
모델 블록
# ---------------------------------------------------------------------------- #
# An implementation of https://arxiv.org/pdf/1512.03385.pdf #
# See section 4.2 for the model architecture on CIFAR-10 #
# Some part of the code was referenced from below #
# https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py #
# ---------------------------------------------------------------------------- #
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copyConv2 d
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)Residual block
# Residual block
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return outResNet
# ResNet
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 16
self.conv = conv3x3(3, 16)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self.make_layer(block, 16, layers[0])
self.layer2 = self.make_layer(block, 32, layers[1], 2)
self.layer3 = self.make_layer(block, 64, layers[2], 2)
self.avg_pool = nn.AvgPool2d(8)
self.fc = nn.Linear(64, num_classes)
def make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if (stride != 1) or (self.in_channels != out_channels):
downsample = nn.Sequential(
conv3x3(self.in_channels, out_channels, stride=stride),
nn.BatchNorm2d(out_channels))
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels
for i in range(1, blocks):
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out모델 학습
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# Hyper-parameters
num_epochs = 80
learning_rate = 0.001
# Image preprocessing modules
transform = transforms.Compose([
transforms.Pad(4),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor()])cuda
train_dataset = torchvision.datasets.CIFAR10(root='../../data/',
train=True,
transform=transform,
download=True)
test_dataset = torchvision.datasets.CIFAR10(root='../../data/',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=100,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=100,
shuffle=False)model = ResNet(ResidualBlock, [2, 2, 2]).to(device)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1def train_model(model, criterion, dataloaders, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 각 에폭(epoch)은 학습 단계와 검증 단계를 갖습니다.
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 모델을 학습 모드로 설정
else:
model.eval() # 모델을 평가 모드로 설정
running_loss = 0.0
running_corrects = 0
# 데이터를 반복
for inputs, labels in dataloaders:
inputs = inputs.to(device)
labels = labels.to(device)
# 매개변수 경사도를 0으로 설정
optimizer.zero_grad()
# 순전파
# 학습 시에만 연산 기록을 추적
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 학습 단계인 경우 역전파 + 최적화
if phase == 'train':
loss.backward()
optimizer.step()
# 통계
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / len(dataloaders)
epoch_acc = running_corrects.double() / len(dataloaders)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# 모델을 깊은 복사(deep copy)함
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 가장 나은 모델 가중치를 불러옴
model.load_state_dict(best_model_wts)
return modelmodel_ft = train_model(model, criterion, train_loader, optimizer, exp_lr_scheduler,
num_epochs=25)Epoch 0/24
----------
train Loss: 184.8816 Acc: 31.5980
val Loss: 164.1515 Acc: 39.0580
.
.
.
Epoch 24/24
----------
train Loss: 82.3157 Acc: 70.8860
val Loss: 80.2452 Acc: 71.5660
Training complete in 16m 7s
Best val Acc: 71.604000
모델 검증
# Test the model
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model_ft(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the model on the test images: {} %'.format(100 * correct / total))Accuracy of the model on the test images: 70.4 %
◼ ReLU (Rectified Linear Unit) 활성함수
▪ 경사도 포화 gradient saturation 문제 해소

◼ 다양한 활성함수들

최근의 활성 함수들은 다음의 문제들을 해결하고자 함
- 포화된 영역이 경사도가 작아짐
- 출력값이 영 중심 아님
- 다소 높은 연산량 (e.g., Exp() 함수)
◼ 배치 정규화 batch normalization
▪ 공변량 시프트 현상을 누그러뜨리기 위해 식 (5.9)의 정규화를 층 단위 적용하는 기법
▪ 정규화를 적용하는 곳이 중요
• 식 (5.15)의 연산 과정 중 식 (5.9)를 어디에 적용하나? (적용 위치)
• 입력 𝐱 또는 중간 결과 𝑧 중 어느 것에 적용? → 𝑧에 적용하는 것이 유리
• 일반적으로 완전연결층, 합성곱층 후 혹은 비선형 함수 전 적용
▪ 훈련집합 전체 또는 미니배치 중 어느 것에 적용? (적용 단위)
• 미니배치에 적용하는 것이 유리
◼ 드롭아웃 dropout 규제 기법
▪ 완전연결층의 노드 중 일정 비율 (일반적으로 p=0.5 적용)을 임의 선택하여 제거 → 남은 부분 신경망 학습

◼ 앙상블 ensemble
▪ 서로 다른 여러 개의 모델을 결합하여 일반화 오류를 줄이는 기법
▪ 현대 기계학습은 앙상블도 규제로 여김
◼ 두 가지 일
1. 서로 다른 예측기를 학습하는 일
• 서로 다른 구조의 신경망 여러 개를 학습 또는 같은 구조를 사용하지만 서로 다른 초기값과 하이퍼 매개변수를 설정하고 학습
• ex) 배깅bagging (bootstrap aggregating) (훈련집합을 여러 번 샘플링하여 서로 다른 훈련집합을 구성)
• ex) 부스팅 boosting (i번째 예측기가 틀린 샘플을 i+1번째 예측기가 잘 인식하도록 연계성을 고려)
2. 학습된 예측기를 결합하는 일 → 모델 평균 model averaging
• 여러 모델의 출력에서 평균을 구하거나 투표하여 최종 결과 결정
Tensor Flow_CNN(DenseNet_test)
Tensor Flow 및 기타 라이브러리 가져오기
from __future__ import absolute_import, division, print_function, unicode_literals
import os
import numpy as np
import matplotlib.pyplot as plt
try:
%tensorflow_version 2.x
except Exception:
pass
import tensorflow as tf
keras = tf.keras
print("tensorflow version",tf.__version__)tensor flow version 2.4.0
IMG_SIZE = 224 # 모든 이미지는 224x224으로 크기 조정
EPOCHS = 2
BATCH_SIZE=16
learning_rate = 0.0001데이터 세트 다운로드 및 탐색
from keras.datasets import cifar10
from keras.utils import np_utils
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
#분류할 클래스 개수
num_classes=10 # Cifar10의 클래스 개수
(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cifar10',
split=['train[:90%]', 'train[90%:]', 'test'],
with_info=True,
as_supervised=True,
)
print("Train data 개수:",len(raw_train))
print("Val data 개수:",len(raw_validation))
print("Test data 개수:",len(raw_test))데이터 정규화(tf.image 모듈을 사용하여 이미지를 정규화)
def format_example(image, label):
image = tf.cast(image, tf.float32)
image = (image/127.5) - 1
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, label# #map 함수를 사용하여 데이터셋의 각 항목에 데이터 포맷 함수를 적용
train = raw_train.map(format_example)
validation = raw_validation.map(format_example)
test = raw_test.map(format_example)데이터 세트 만들기
SHUFFLE_BUFFER_SIZE = 1000
train_batches = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation_batches = validation.batch(BATCH_SIZE)
test_batches = test.batch(BATCH_SIZE)데이터 검사하기
#데이터 가시화
get_label_name = metadata.features['label'].int2str
for image, label in raw_train.take(2):
plt.figure()
plt.imshow(image)
plt.title(get_label_name(label))

사용할 CNN 모델 불러오기
IMG_SHAPE = (IMG_SIZE, IMG_SIZE, 3)
#CNN 모델 변경하려면 여기서 변경
#ImageNet으로 사전 훈련된 모델 불러오기
base_model = tf.keras.applications.DenseNet121(input_shape=IMG_SHAPE,
include_top=False,
classes=1000,
weights='imagenet')base_model.summary()Model: "densenet121" __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_1 (InputLayer) [(None, 224, 224, 3) 0
.
.
.
relu (Activation) (None, 7, 7, 1024) 0 bn [0][0] ================================================================================================== Total params: 7,037,504 Trainable params: 6,953,856 Non-trainable params: 83,648 ________________________________________________________________________________________________
불러온 모델에서 데이터 셋의 클래스 수에 맞게 최종 분류층 교체
#GAP 층
global_average_layer = tf.keras.layers.GlobalAveragePooling2D(name='avg_pool')
#분류 층
prediction_layer=keras.layers.Dense(num_classes, activation='softmax',name='predictions')
model = tf.keras.Sequential([
base_model,
global_average_layer,
prediction_layer
])모델 아키텍처 살펴보기
model.summary()Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= densenet121 (Functional) (None, 7, 7, 1024) 7037504 _________________________________________________________________ avg_pool (GlobalAveragePooli (None, 1024) 0 _________________________________________________________________ predictions (Dense) (None, 10) 10250 ================================================================= Total params: 7,047,754 Trainable params: 6,964,106 Non-trainable params: 83,648 _________________________________________________________________
모델 컴파일
model.compile(optimizer=tf.keras.optimizers.Adam(lr=learning_rate),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])Epoch 1/2 2813/2813 [==============================] - 540s 186ms/step - loss: 0.5497 - accuracy: 0.8153 - val_loss: 0.1805 - val_accuracy: 0.9360 Epoch 2/2 2813/2813 [==============================] - 520s 185ms/step - loss: 0.1776 - accuracy: 0.9403 - val_loss: 0.1670 - val_accuracy: 0.9400
학습 곡선 그리기
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
Test Set으로 학습된 모델 테스트
loss_and_metrics = model.evaluate(test_batches, batch_size=64)
print("테스트 성능 : {}%".format(round(loss_and_metrics[1]*100,4)))625/625 [==============================] - 29s 47ms/step - loss: 0.1917 - accuracy: 0.9383 테스트 성능 : 93.83%
◼ 시간성 time series 데이터
▪ 특징이 순서를 가지므로 순차 데이터 sequential data라 부름 (지금까지 다룬 데이터는 어느 한순간에 취득한 정적인 데이터이고 고정 길이임 fixed input)
▪ 순차 데이터는 동적이며 보통 가변 길이임 variable-length input
◼ 순환 신경망 recurrent neural networks과 LSTM
▪ 순환 신경망은 시간성 정보를 활용하여 순차 데이터를 처리하는 효과적인 학습 모델
▪ 매우 긴 순차 데이터 (예, 30 단어 이상의 긴 문장)를 처리에는 장기 의존성 long-term dependency을 잘 다루는 LSTM을 주로 사용 (LSTM은 선별 기억 능력을 가짐)
◼ 문맥 의존성 ▪ 비순차 데이터는 공분산이 특징 사이의 의존성을 나타냄
▪ 순차 데이터에서는 공분산은 의미가 없고, 대신 문맥 의존성이 중요함
• ex) “그녀는 점심때가 다 되어서야 …. 점심을 먹었는데, 철수는 …”에서 “그녀는”과 “먹었는데”는 강한 문맥 의존성을 가짐
• 특히 이 경우 둘 사이의 간격이 크므로 장기 의존성이라 부름 ← LSTM으로 처리
◼ RNN의 구조
▪ 기존 깊은 신경망과 유사
• 입력층, 은닉층, 출력층을 가짐
▪ 다른 점은 은닉층이 순환 연결 recurrent edge (recurrent connection)를 가진다는 점
• 시간성, 가변 길이, 문맥 의존성을 모두 처리할 수 있음
• 순환 연결은 t-1 순간에 발생한 정보를 t 순간으로 전달하는 역할

◼ LSTM 핵심 요소
▪ 메모리 블록 (셀): 은닉 상태 hidden state 장기 기억
▪ 망각 forget 개폐구 (1: 유지, 0: 제거): 기억 유지 혹은 제거
▪ 입력 input 개폐구: 입력 연산
▪ 출력 output 개폐구: 출력 연산

Pytorch Tutoral - RNN
from IPython.display import Image
Image('rnn1.png')
from IPython.display import Image
Image('lstm1.png')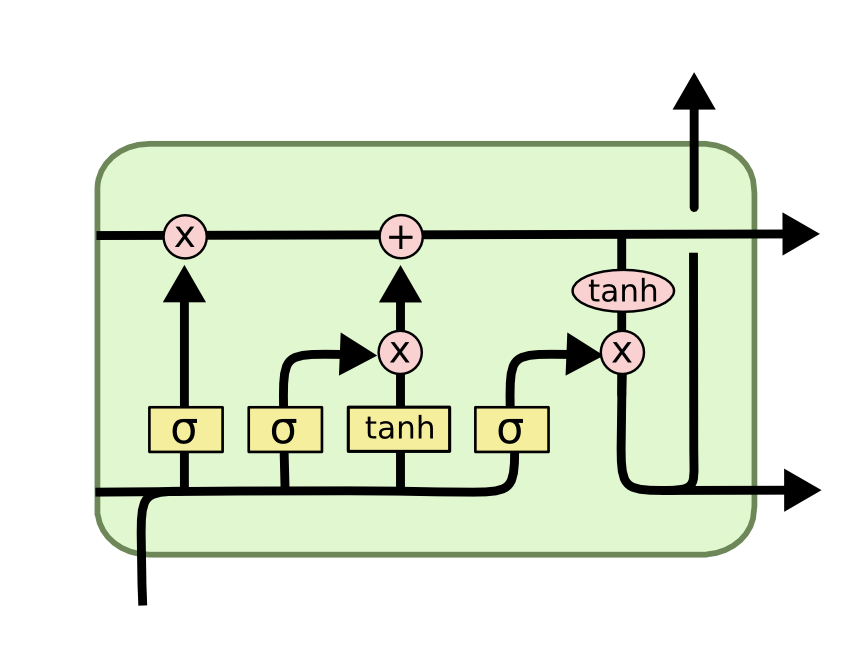
import torch
import torch.nn as nn
print(torch.__version__)1.7.0+cu101
# RNN 예시
rnn = nn.RNN(3, 3) # Input dim is 3, output dim is 3
inputs = [torch.randn(1, 3) for _ in range(5)] # sequence의 크기가 5
print('inputs : ', inputs)
# initialize the hidden state.
hidden = (torch.randn(1, 1, 3))
for i in inputs:
# 한 스텝에서 하나의 sequence를 입력으로
# 각 스텝이 끝날 때마다 hidden 값은 연결됨
out, hidden = rnn(i.view(1, 1, -1), hidden)
print('out: ', out)
print('out shape: ', out.shape)
print('hidden: ', hidden)
print('hidden shape: ', hidden.shape)
inputs : [tensor([[ 0.1375, 1.5049, -1.2597]]), tensor([[ 0.5901, -2.5640, 0.7672]]), tensor([[ 0.4766, -1.1615, -0.0617]]), tensor([[ 1.3723, -1.0715, -1.2721]]), tensor([[ 0.1172, -2.4750, -1.2411]])]
out: tensor([[[ 0.8476, -0.2891, 0.9473]]], grad_fn=<StackBackward>)
out shape: torch.Size([1, 1, 3])
hidden: tensor([[[ 0.8476, -0.2891, 0.9473]]], grad_fn=<StackBackward>)
hidden shape: torch.Size([1, 1, 3])
# LSTM 예시
lstm = nn.LSTM(3, 3) # Input dim is 3, output dim is 3
inputs = [torch.randn(1, 3) for _ in range(5)] # sequence의 크기가 5
print('inputs : ', inputs)
# initialize the hidden state.
hidden = (torch.randn(1, 1, 3),
torch.randn(1, 1, 3))
for i in inputs:
# 한 스텝에서 하나의 sequence를 입력으로
# 각 스텝이 끝날 때마다 hidden 값은 연결됨
out, hidden = lstm(i.view(1, 1, -1), hidden)
print('out: ', out)
print('out shape: ', out.shape)
print('hidden: ', hidden)
print('hidden state shape: ', hidden[0].shape)
print('cell state shape: ', hidden[1].shape)
inputs : [tensor([[0.1083, 0.6724, 0.3088]]), tensor([[-1.9268, -0.9541, 0.2925]]), tensor([[-1.0944, 0.4967, -1.1188]]), tensor([[ 1.9047, 0.7680, -0.6291]]), tensor([[-0.9119, 0.0491, -1.0373]])]
out: tensor([[[-0.0692, 0.1055, 0.1168]]], grad_fn=<StackBackward>)
out shape: torch.Size([1, 1, 3])
hidden: (tensor([[[-0.0692, 0.1055, 0.1168]]], grad_fn=<StackBackward>), tensor([[[-0.1493, 0.2938, 0.2025]]], grad_fn=<StackBackward>))
hidden state shape: torch.Size([1, 1, 3])
cell state shape: torch.Size([1, 1, 3])
'BOOTCAMP > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
| [13주차] monthly project3 (0) | 2023.06.28 |
|---|---|
| [12주차] SQL과 데이터분석 (0) | 2023.06.27 |
| [10주차] 신경망 기초 (0) | 2023.06.24 |
| [9주차] ML_basics - Linear Regression (0) | 2023.06.23 |
| [8주차 - Day3] 케글 경진대회 - Spaceship Titanic (0) | 2023.06.23 |



