
1. Big Data: 데이터 팀의 역할
- 데이터 팀의 미션
신뢰할 수 있는 데이터를 바탕으로 부가가치 생성, 데이터는 새로운 오일 등이라고 하지만, 항상 데이터 팀의 부가가치를 창출하는 것. 사측에서 기대하는 만큼, 어떤 이익을 창출해 줄지 고민해야 함.
- 데이터 팀의 목표 1
-고품질의 데이터를 제공하여 정책 결정에 사용
-결정과학(Decision Science)라고 부르기도 함
데이터 참고 결정(data informed decisions)을 가능하게 함
vs. 데이터 기반 결정(data driven decisions)
- 데이터 팀의 목표 2
-고품질 데이터를 필요할 때 제공하여 사용자의 서비스 경험 개선
머신 러닝과 같은 데이터 기반 알고리즘을 통해 개선
예) 개인화를 바탕으로한 추천(Recommendation)과 검색 기능 제공
하지만 사람의 개입/도움이 반드시 필요(human-in-the-loop)
- 데이터 팀의 발전 - 1. 데이터 인프라 구축
-데이터 인프라: 데이터 웨어하우스와 ETL(Extract, Transform, Load)
데이터 웨어하우스: 회사에 필요한 모든 데이터들을 저장하는 중앙 데이터베이스
ETL(Extract, Transform, Load): 소스에 존재하는 데이터들을 데이터 웨어하우스로 복사해 오는 코드를 지칭, 보통 파이썬으로 작성
-데이터 인프라의 구축은 데이터 엔지니어가 수행함
- 데이터 웨어하우스란?
-회사에 필요한 모든 데이터를 모아놓은 중앙 데이터베이스(SQL)
데이터의 크기에 맞게 어떤 데이터베이스를 사용할지 선택
크기가 커진다면 AWS의 Redshift, 구글 클라우드의 BigQuery, 스노우플레이크(Snowflake)나 오픈소스 기반의 하둡/스파크를 사용하는 것을 추천: 이 모두 SQL을 지원
-중요 포인트는 프로덕션용 데이터베이스와 별개의 데이터베이스라는 점
-데이터 웨어하우스 구축은 진정한 데이터 조직이 되는 첫번째 스텝
- ETL(Extract, Transform, Load)이란? (1)
-다른 곳에 존재하는 데이터를 가져다가 데이터 웨어하우스에 로드하는 작업
Extract: 외부 데이터 소스에서 데이터를 추출
Transform: 데이터의 포맷을 원하는 형태로 변환
Load: 변환된 데이터를 최종적으로 데이터 웨어하우스로 적재
- ETL(Extract, Transform, Load)이란? (2)
-이는 코딩을 필요로 하며 가장 많이 쓰이는 프레임 워크는 Airflow
Airflow는 오픈소스 프로젝트 파이썬3 기반
에어비앤비, 우버, 리프트, 쿠팡 등에서 사용
AWS와 구글클라우드에서도 지원
흔한 데이터 소스의 경우 SaaS(Software as a Service) 사용 가능
FiveTran, Stitch Data, …
- 데이터 팀의 발전 - 2. 데이터 분석 수행
-데이터 분석이란?
회사와 팀별 중요 지표(metrics) 정의하고, 대시보드 형태로 시각화(visualization)
이외에도 데이터와 관련한 다양한 분석/리포팅 업무 수행
중요 지표의 예: 매출액, 월간/주간 액티브 사용자수, …
이는 데이터 분석가 (Data Analyst)가 맡는 일임
- 시각화 대시보드란?
-보통 중요한 지표를 시간의 흐름과 함께 보여주는 것이 일반적
지표의 경우 3A(Accessible, Actionable, Auditable)가 중요
-가장 널리 사용되는 대시보드:
구글 클라우드의 룩커(Looker)
세일즈포스의 태블로(Tableau)
마이크로소프트의 파워 BI(Power BI)
오픈소스 아파치 수퍼셋(Superset)
2. Big Data: 데이터 팀의 구성원
- 데이터 엔지니어(Data Engineer)
- 데이터 인프라(데이터 웨어하우스와 ETL) 구축
- 데이터 분석가(Data Analyst)
- 데이터 웨어하우스의 데이터를 기반으로 지표를 만들고 시각화 (대시보드)
- 내부 직원들의 데이터 관련 질문 응답
- 데이터 과학자(Data Scientist)
- 과거 데이터를 기반으로 미래를 예측하는 머신러닝 모델을 만들어 고객들의 서비스 경험을 개선 (개인화 혹은 자동화 혹은 최적화)
- 작은 회사에서는 한 사람이 몇개의 역할을 동시에 수행하기도 함
- 데이터 엔지니어의 역할
- 기본적으로 소프트웨어 엔지니어
- 파이썬이 대세, 자바 혹은 스칼라와 같은 언어도 아는 것이 좋음
- 데이터 웨어하우스 구축
- 데이터 웨어하우스를 만들고, 이를 관리. 클라우드로 가는 것이 추세
- AWS의 Redshift, 구글클라우드의 BigQuery, 스노플레이크
- 관련해서 중요한 작업 중의 하나는 ETL 코드를 작성하고, 주기적으로 실행해 주는 것
- ETL 스케줄러 혹은 프레임웍이 필요 (Airflow라는 오픈소스가 대세)
- 데이터 분석가와 과학자 지원
- 데이터 분석가, 데이터 과학자들과의 협업을 통해 필요한 툴이나 데이터를 제공해 주는 것이 데이터 엔지니어의 중요한 역할 중의 하나
- 데이터 웨어하우스를 만들고, 이를 관리. 클라우드로 가는 것이 추세
- 기본적으로 소프트웨어 엔지니어
- 머신러닝 모델링 사이클
- 보통 A/B 테스트를 통해 이뤄짐
- 가설 → 데이터 수집, 분석, 모델개발, 모델 론칭, 테스트 시작 → 비즈니스 개선(매출증대, 경비절약)
- 보통 A/B 테스트를 통해 이뤄짐
- 폭포수 개발방법론 vs. 애자일 개발방법론
Requirements → Design → Implementation → Verification → Maintenance

한 사이클을 빠르게 돌리면, 접근 방법에 대한 아이디어가 생김. 문제에 대해 더 이해하고, 어떤 이슈가 있는지 포텐셜 한 문제를 해결할 수 있있습니다.
- A/B 테스트란? (1)
- 온라인 서비스에서 새 기능의 임팩트를 객관적으로 측정하는 방법
- 의료 쪽에서 무작위 대조 시험(Randomized Controlled Trial)
- 새로운 기능을 론칭함으로 생기는 위험 부담을 줄이는 방법
- 100%의 사용자에게 론칭하는 것이 아니라 작게 시작하고, 관찰 후 결정
- 실제 예제: 추천을 기계학습기반으로 바꾼 경우
- 먼저 5%의 사용자에게만 론칭하고, 나머지 95%의 사용자와 매출액과 같은 중요 지표를 가지고 비교
- 5% 대상으로 별문제 없으면 10%, 20% 이런 식으로 점진적으로 키우고, 최종적으로 100%로 론칭
- 온라인 서비스에서 새 기능의 임팩트를 객관적으로 측정하는 방법
- A/B 테스트란? (2)
- 보통 사용자들을 2개의 그룹으로 나누고, 시간을 두고 관련 지표를 비교
- 한 그룹은 기존 기능에 그대로 노출(control)
- 다른 그룹은 새로운 기능에 노출(test)
- 가설과 영향받는 지표를 미리 정하고, 시작하는 것이 일반적
- 지표의 경우 성공/실패 기준까지 생각해 보는 것이 중요
- 보통 사용자들을 2개의 그룹으로 나누고, 시간을 두고 관련 지표를 비교
- 중앙집중 구조: 모든 데이터 팀원들이 하나의 팀으로 존재
- 일의 우선순위는 중앙 데이터팀이 최종 결정
- 데이터 팀원들간의 지식과 경험의 공유가 쉬워지고, 커리어 경로가 더 잘 보임
- 하지만 현업부서들의 만족드는 상대적으로 떨어짐
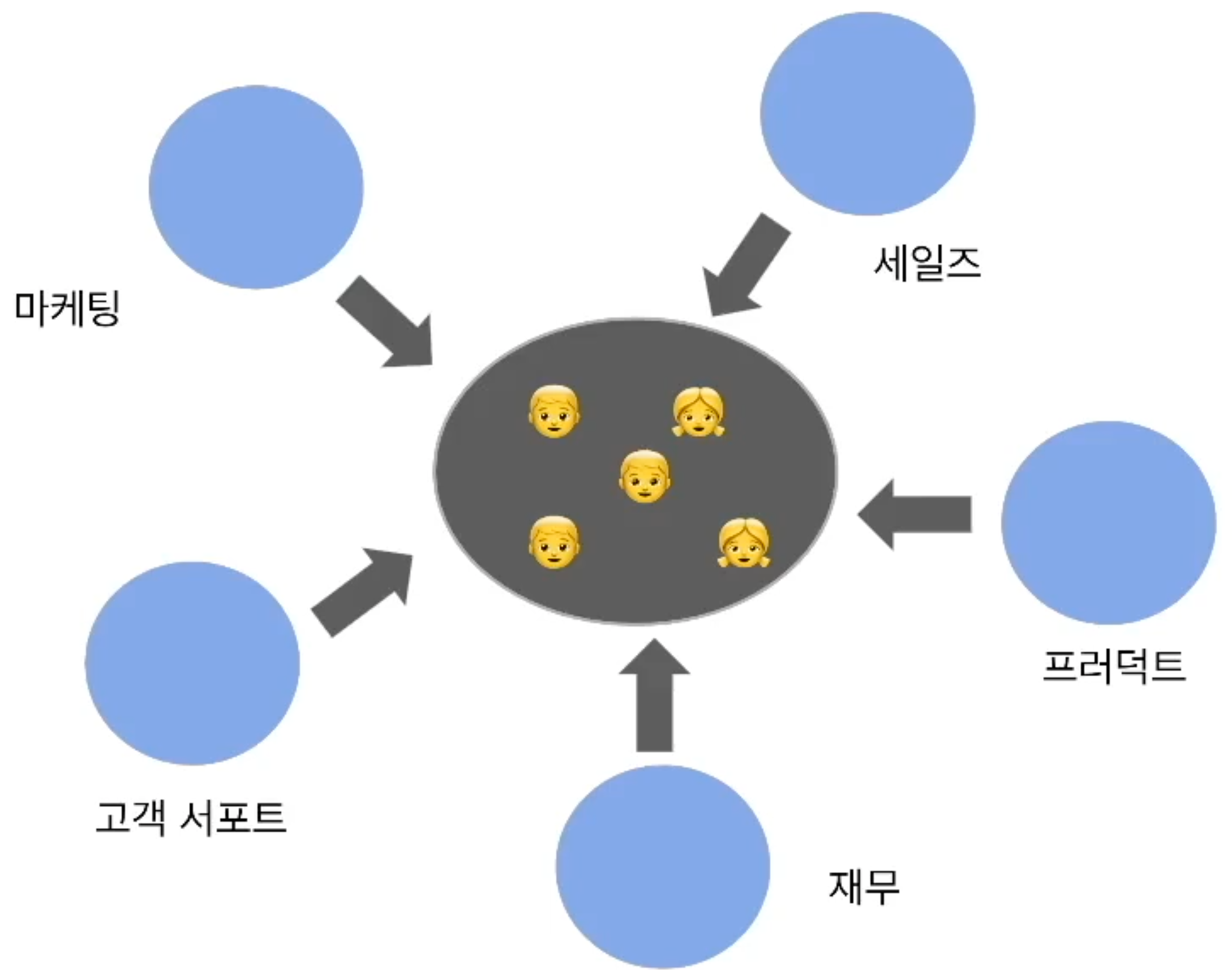
- 분산 구조: 데이터팀이 현업 부서별로 존재
- 일의 우선 순위는 각 팀별로 결정
- 데이터 일을 하는 사람들 간의 지식/경험의 공유가 힘들고, 데이터 인프라나 데이터의 공유가 힘들어짐
- 현업부서들의 만족도는 처음에는 좋지만, 많은 수의 데이터 팀원들이 회사를 그만두게 됨

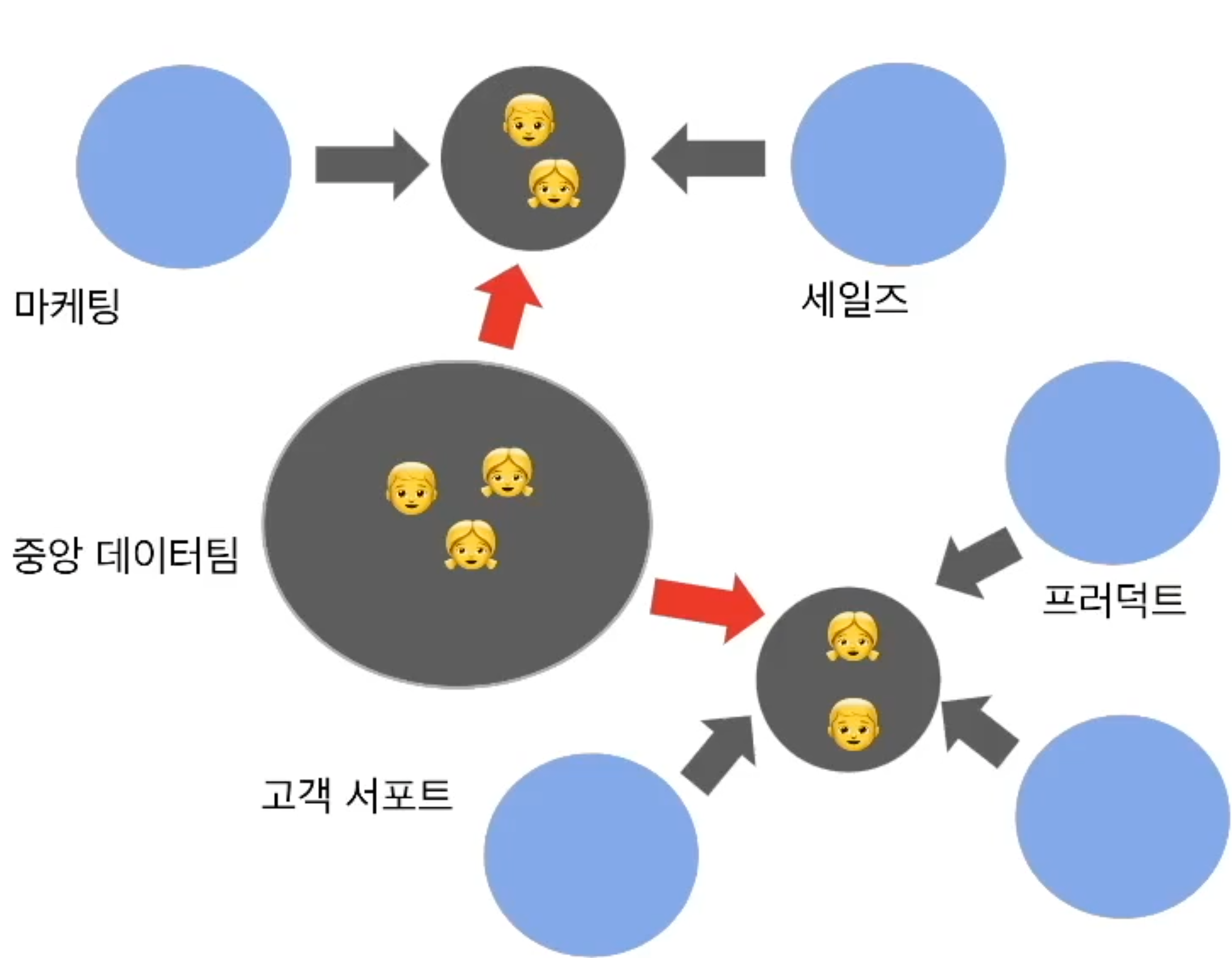
- 중앙집중과 분산의 하이브리드 모델
- 가장 이상적인 조직 구조
- 데티어 팀원들의 일부는 중앙에서 인프라적인 일을 수행하고, 일부는 현업팀으로 파견식으로 일하되 주기적으로 일을 변경
- 데이터팀 안에서 커리어 경로가 만들어짐
- 데이터 인프라가 첫 번째 스텝
- 데이터 인프라 없이는 데이터 분석이나 모델링은 불가능
- 하지만 아주 작은 회사에서 생존이 더 중요한 문제라 데이터 인프라는 조금 더 성장한 뒤에 걱정해도 됨
- 첫 번째 팀원은 인프라 구축 이외에도 약간의 분석/모델링 스킬이 있는 사람이 최적
- 고려점
- 클라우드 vs. 직접 구성
- 배치 vs. 실시간: 처음부터 실시간으로 할 필요 없음
- 데이터 인프라 없이는 데이터 분석이나 모델링은 불가능
Big Data: Spark 소개
- 빅데이터의 정의와 예
- 빅데이터의 정의 1
- “서버 한대로 처리할 수 없는 규모의 데이터”
- 2012년 4월 아마존 클라우드 콘퍼런스에서 아마존의 data scientist인 존 라우저(John Rauser)가 내린 정의 분산 환경이 필요하냐에 포커스
- 판다스로 처리해야 할 데이터가 너무 커서 처리가 불가능하다면 어떻게 할 것인가?
- 빅데이터의 정의 2
- “기존의 소프트웨어로는 처리할 수 없는 규모의 데이터”
- 대표적인 기존 소프트웨어 오라클이나 MySQL과 같은 관계형 데이터베이스
- 분산환경을 염두에 두지 않음
- Sclae-up 접근방식 (vs. Scale-out)
- 메모리 추가, CPU 추가, 디스크 추가
- 빅데이터의 정의 3
- 4V(Volume, Velocity, Variety, Varecity)
- Volume: 데이터의 크기가 대용량
- Velocity: 데이터의 처리 속도가 중요
- Variety: 구조화/비구조화 데이터 둘 다
- Veracity: 데이터의 품질이 좋은지
- 빅데이터의 예제 - 디바이스 데이터
- 모바일 디바이스
- 위치정보
- 스마트 TV
- 각종 센서 데이터 (IoT 센서)
- 네트워킹 디바이스
- 모바일 디바이스
- 빅데이터의 예 - 웹 페이지
- 수십조 개 이상의 웹 페이지 존재
- 이를 크롤링하여 중요한 페이지를 찾아내고 (페이지 랭크) 인덱싱하는 것은 엄청난 크기의 데이터 수집과 계산을 필요로 함
- 사용자 검색어와 클릭 정보 자체도 대용량
- 이를 마이닝하여 개인화 혹은 별도 서비스 개발이 가능
- 검색어 자동 완성, 동의어 찾기, 통계 기반 번역
- 이를 마이닝하여 개인화 혹은 별도 서비스 개발이 가능
- 이런 문제를 해결하면서 구글이 빅데이터 기술의 발전에 지대한 공헌을 하게 됨
- 빅데이터의 정의 1
하둡의 등장과 소개
-기존 기술과는 전혀 다른 방식을 택함으로써 대용량 데이터 처리를 가능하게 해 준 하둡에 대해 알아보자
- 대용량 처리 기술이란?
- 분산 환경 기반(1대 혹은 그 이상의 서버로 구성)
- 분산 컴퓨팅과 분산 파일 시스템이 필요
- Fault Tolerance
- 소수의 서버가 고장 나도 동작해야 함
- 확장이 용이해야 함
- Scale Out이라고 부름
- 분산 환경 기반(1대 혹은 그 이상의 서버로 구성)
- 하둡(Hadoop)의 등장
- Doug Cutting이 구글랩 발표 논문들에 기반해 만든 오픈소스 프로젝트
- 2003년 The Google File System
- 2004년 MapReduce: Simplified Data Processing on Large Cluster
- 처음 시작은 Nutch라는 오픈소스 검색엔진의 하부 프로젝트
- 하둡은 Doug Cutting의 아들의 코끼리 인형의 이름
- 2006년에 아파치 톱레벨 별개 프로젝트로 떨어져 나옴
- 크게 두 개의 서브 시스템으로 구현됨
- 분산 파일 시스템인 HDFS
- 분산 컴퓨팅 시스템 MapReduce
- 새로운 프로그래밍 방식으로 대용량 데이터 처리의 효율을 극대화하는데 맞춤
- Doug Cutting이 구글랩 발표 논문들에 기반해 만든 오픈소스 프로젝트
- MapReduce 프로그래밍의 문제점
- 작업에 따라서는 MapReduce 프로그래밍이 너무 복잡해짐
- 결국 Hive처럼 MapReduce로 구현된 SQL 언어들이 다시 각광을 받게 됨
- SQL in Hadoop
- 빅데이터가 뜨면서 SQL이 한물갔다가 평가되었지만, 다시 각광을 받음
- 또한 MapReduce는 기본적으로 배치 작업에 최적화 (not realtime)
SQL는 소규모 데이터 처리에 필요? MapReduce의 복잡성에 의해 다시금 SQL 각광
- 하둡(Hadoop)의 발전
- 하둡 1.0은 HDFS위에 MapReduce라는 분산컴퓨팅 시스템이 도는 구조
- 다른 분산컴퓨팅 시스템은 지원하지 못함
- 하둡 2.0에서 아키텍처가 크게 변경됨
- 하둡은 기반 분산처리 시스템이 되고, 그 위에 애플리케이션 레이어가 올라가는 구조
- Spark은 하둡 2.0위에서 어플리케이션 레이어로 실행됨
- 손쉬운 개발을 위한 로컬 모드도 지원: 이번 강좌에서는 로컬 모드 사용
- 하둡 1.0은 HDFS위에 MapReduce라는 분산컴퓨팅 시스템이 도는 구조
- HDFS - 분산 파일 시스템
- 데이터를 블록단위로 저장
- 블록의 크기는 128MB(디폴트)
- 블록 복제 방식 (Replication)
- 각 블록은 3군데에 중복 저장됨
- Fault tolerance를 보장할 수 있는 방식으로 이 블록들은 저장됨
- 데이터를 블록단위로 저장
Spark 소개
하둡은 1세대 빅데이터 처리기술이라면 Spark은 2세대 빅데이터 기술이라 할 수 있습니다.
- Spark의 등장
- 버클리 대학의 AMPLab에서 아파치 오픈소스 프로젝트로 2013년 시작
- 나중에 DataBricks라는 스타트업 창업
- 하둡의 뒤를 잇는 2세대 빅데이터 기술
- 하둡 2.0을 분산환경으로 사용 가능
- 자체 분산환경도 지원함
- Scala로 작성됨
- 하둡 2.0을 분산환경으로 사용 가능
- MapReduce의 단점을 대폭적으로 개선
- Pandas와 굉장히 흡사 (서버 한대 버전 vs. 다수 서버 분산환경 버전)
- 현재 Spark 버전 3이며 이번 강좌에서는 이를 사용
- 현재 Scala, Java, Python 3으로 프로그래밍이 가능
- 머신 러닝 관련해서 많은 개선이 있었음 (GPU 지원 포함)
- 버클리 대학의 AMPLab에서 아파치 오픈소스 프로젝트로 2013년 시작
- Spark vs. MapReduce
- Spark은 기본적으로 메모리 기반
- 메모리가 부족해지면 디스크 사용
- MapReduce는 디스크 기반
- MapReduce는 하둡 위에서만 동작
- Spark은 하둡(YARN) 이외에도 다른 분산 컴퓨팅 환경 지원
- MapReduce는 키와 밸류 기반 프로그래밍
- Spark은 판다스와 개념적으로 흡사
- Spark은 다양한 방식의 컴퓨팅을 지원
- 배치 프로그래밍, 스트리밍 프로그래밍, SQL, 머신 러닝, 그래프 분석
- Spark은 기본적으로 메모리 기반
- Spark의 구조
- 드라이버 프로그램의 존재
- Spark은 하둡 2.0(혹은 하둡 3.0) 위에 올라가는 어플리케이션
- Spark 프로그래밍 개념
- RDD (Resilient Distributed Dataset)
- 로우레벨 프로그래밍 API로 세밀한 제어가 가능
- 하지만 코딩의 복잡도 증가
- Dataframe & Dataset (판다스의 데이터프레임과 흡사)
- 하이레벨 프로그래밍 API로 점점 많이 사용되는 추세
- SparkSQL을 사용한다면 이를 쓰게 됨
- 보통 Scala, Java, Python 중의 하나를 사용
- PySpark 모듈
- RDD (Resilient Distributed Dataset)
- Spark 세션
- Spark 프로그램의 시작은 Spark 세션(SparkSession)을 만드는 것
- Spark 세션을 통해 Spark이 제공해 주는 다양한 기능을 사용
- Spark 콘텍스트, Hive 컨텍스트, SQL 컨텍스트
- Spark 2.0 전에는 기능에 따라 다른 콘텍스트를 생성해야 했음
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark create RDD example") \
.config("spark.some.config.option", "some-value") \
.getOrcreate()
sc = spark.sparkContextspark와 sc를 이용해 RDD와 데이터프레임을 조작하게 됨
- Spark 데이터 구조
- 크게 3가지의 자료구조가 존재
- RDD (Resilient Distributed Dataset)
- 로우레벨 데이터로 클러스터 내의 서버에 분산된 데이터를 지칭
- 레코드별로 존재하며 구조화된 데이터나 비구조화된 데이터 모두 지원
- Dataframe과 Dataset
- RDD위에 만들어지는 하이레벨 데이터로 RDD와는 달리 필드 정보를 갖고 있음 (테이블)
- Dataset은 Dataframe과는 달리 타입 정보가 존재하며 컴파일 언어에서 사용가능
- 컴파일 언어: Scala/Java에서 사용가능
- PySpark에서는 Dataframe을 사용함
- SparkSQL을 사용하는 것이 더 일반적
- RDD (Resilient Distributed Dataset)
- 크게 3가지의 자료구조가 존재
- Spark 데이터 구조 - RDD
- 변경이 불가능한 분산 저장된 데이터
- RDD는 다수의 파티션으로 구성되고, Spark 클러스터내 서버들에 나눠 저장됨
- 로우레벨의 함수형 변환 지원 (map, filter, flatMap 등등)
- RDD가 아닌 일반 파이썬 데이터는 parallelize 함수로 RDD로 변환
- 변경이 불가능한 분산 저장된 데이터
- SparkSQL이란?
- SparkSQL은 구조화된 데이터 처리를 위한 Spark 모듈
- 대화형 Spark 셸이 제공됨
- 하둡 상의 데이터를 기반으로 작성된 Hive 쿼리의 경우 변경 없이 최대 100배까지 빠른 성능을 가능하게 해 줌
- 데이터 프레임을 SQL로 처리 가능
- RDD 데이터는 결국 데이터 프레임으로 변환한 후에 처리 가능
- 외부 데이터 (스토리지나 관계형 데이터베이스)는 데이터프레임으로 변환한 후 가능
- 데이터프레임은 테이블이 되고 (특정 함수 사용) 그다음부터 sql함수를 사용가능
- SparkSQL 사용법 - 외부 데이터베이스 연결 (1)
- 외부 데이터베이스 기반으로 데이터 프레임 생성
- SparkSession의 read 함수를 사용하여 테이블 혹은 SQL 결과를 데이터프레임으로 읽어옴
- Redshift 연결 예제
- SparkSession을 만들 때 외부 데이터베이스에 맞는 JDBC jar을 지정
- SparkSession의 read 함수를 호출
- 로그인 관련 정보와 읽어오고자 하는 테이블 혹은 SQL을 지정
- 결과가 데이터 프레임으로 리턴됨
- 앞서 리턴된 데이터프레임에 테이블 이름 지정
- SparkSession의 sql 함수를 사용
- 외부 데이터베이스 기반으로 데이터 프레임 생성
- SparkSQL 사용법 - 외부 데이터베이스 연결 (2)
- SparkSession을 만들때 외부 데이터베이스에 맞는 JDBC jar을 지정
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example")\
.config("spark.jars",
"/usr/local/lib/python3.6/dist-packages/pyspark/jars/RedshiftJDBC42-no-awssdk-1.- SparkSQL 사용법 - 외부 데이터베이스 연결 (3)
- Spark Session의 read 함수를 호출(로그인 관련 정보와 읽어오고자 하는 테이블 혹은 SQL을 지정) 결과가 데이터 프레임으로 리턴됨
df_user_session_channel = spark.read\
.format("jdbc")\
.option("driver", "com.amazon.redshift.jdbc42.Driver")\
.option("url, ...- SparkSQL 사용법 - SQL 사용 방법
- 데이터 프레임을 기반으로 테이블 뷰 생성: 테이블이 만들어짐
- createOrReplace TempView: sparkSession이 살아있는 동안 존재
- createGlobalTempView: Spark 드라이버가 살아있는 동안 존재
- Spark Session의 sql 함수로 SQL 결과를 데이터 프레임으로 받음
- 데이터 프레임을 기반으로 테이블 뷰 생성: 테이블이 만들어짐
Big Data: Spark MLlib 소개와 머신러닝 모델 빌딩
- Spark MLib 소개 (1)
- 머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리
- Classification, Regression, Clustering, Collaborative Filtering, Dimensionality Reduction.
- 아직 딥러닝은 지원이 미약
- 여기에는 RDD 기반과 데이터프레임 기반의 두 버전이 존재
- spark.mllib vs. spark.ml
- spark.mllib가 RDD 기반이고, spark.ml은 데이터프레임 기반
- spark.mllib는 RDD위에서 동작하는 이전 라이브러리로 더 이상 업데이트가 안됨
- 항상 spark.ml을 사용할 것
- import pyspark.ml
- spark.mllib vs. spark.ml
- 머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리
- Spark MLlib의 장점
- 원스톱 ML 프레임워크
- 데이터프레임과 SparkSQL 등을 이용해 전처리
- Spark MLlib를 이용해 모델 빌딩
- ML Pipeline을 통해 모델 빌딩 자동화
- MLflow로 모델 관리하고 서빙
- 대용량 데이터도 처리 가능
- 원스톱 ML 프레임워크
- Spark MLlib 소개: MLflow
- 모델의 관리와 서빙을 위한 Ops 관련 기능도 제공
- MLflow
- 모델 개발과 테스트와 관리와 서빙까지 제공해 주는 End-to-End 프레임워크
- MLflow는 파이썬, 자바, R, API를 지원
- MLflow는 트래킹(Tracking), 모델(Models), 프로젝트(Projects)를 지원
- Spark MLlib 제공 알고리즘
- Classification:
- Logistic regression, Decision tree, Randaom forest, Gradient-boosted tree, …
- Regression:
- Linear regression, Decision tree, Random forest, Gradient-boosted tree, …
- Clustering:
- K-means, LDA(Latent Dirichlet Allocation), GMM(Gaussian Mixture Model), …
- Collaborative Filtering
- 명시적인 피드백과 암묵적인 피드백 기반
- 명시적인 피드백의 예) 리뷰 평점
- 암묵적인 피드백의 예) 클릭, 구매 등등
- Classification:
→ 명시적인 피드백을 하는 게 좋지만, 그렇지 못할 시엔 암묵적인 피드백이 진행됨
'BOOTCAMP > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
| [16주차] NLP II와 Visual Recognition (0) | 2023.07.21 |
|---|---|
| [15주차] NLP (0) | 2023.06.28 |
| [13주차] monthly project3 (0) | 2023.06.28 |
| [12주차] SQL과 데이터분석 (0) | 2023.06.27 |
| [11주차] CNN & RNN (0) | 2023.06.27 |



