2023. 4. 6. 14:26ㆍBOOTCAMP/프로그래머스 인공지능 데브코스

EDA
데이터 그 자체만으로부터 인사이트를 얻어내는 접근법으로 numpy, pandas 사용
분석의 목적과 변수를 확인하고, 데이터를 전체적으로 살펴보며 데이터의 개별 속성을 파악해야 합니다.
EDA with Example - Titanic
분석의 목적과 변수 확인
살아남은 사람들은 어떤 특징을 가지고 있었을까?

Exploratory Data Analysis
0. 라이브러리 준비
## 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
## 동일 경로에 "train.csv"가 있다면
## 데이터 불러오기
titanic_df = pd.read_csv("/Users/xxxxxxx/Desktop/titanic/train.csv")
1. 분석의 목적과 변수 확인
- 타이타닉 호에서 생존한 생존자들은 어떤 사람들일까?
## 상위 5개 데이터 확인하기
titanic_df.head(5)
## 각 column의 데이터 타입 확인하기
titanic_df.dtypesPassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
2. 데이터 전체적으로 살펴보기
## 데이터 전체 정보를 얻는 함수: .describe()
titanic_df.describe() # 수치형 데이터에 대한 요약만을 제공
## 상관계수 확인
titanic_df.corr()
# Correlation is NOT Causation
# 상관성 : A up, B up, ...
# 인과성 : A -> B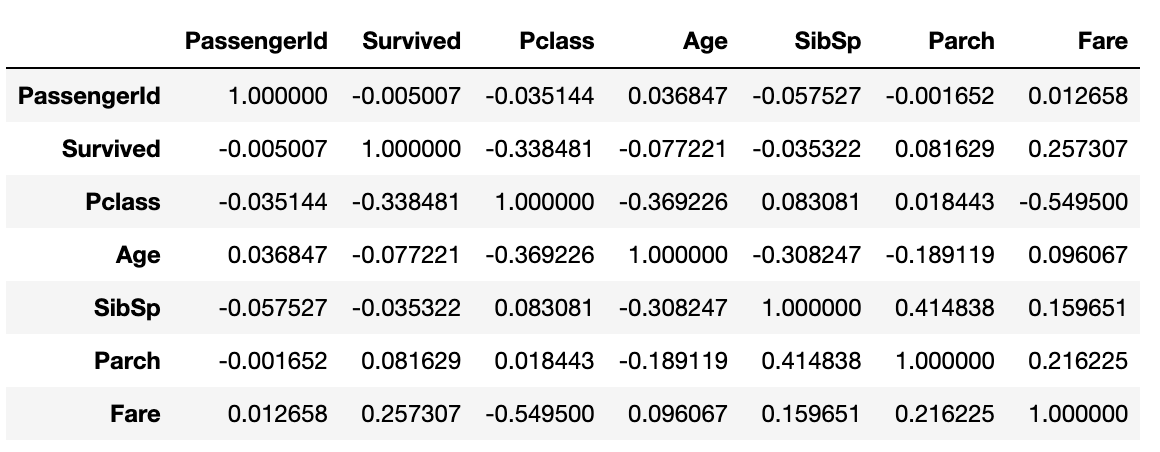
## 결측치 확인
titanic_df.isnull().sum()
# Age, Cabin, Embarked에서 결측치 확인PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
3. 데이터의 개별 속성 파악하기
1. Survived Column
## 생존자, 사망자 명수는?
titanic_df['Survived'].value_counts()0 549
1 342
Name: Survived, dtype: int64
## 생존자수와 사망자수를 Barplot으로 그려보기 sns.countplot()
sns.countplot(x='Survived', data=titanic_df)
plt.show()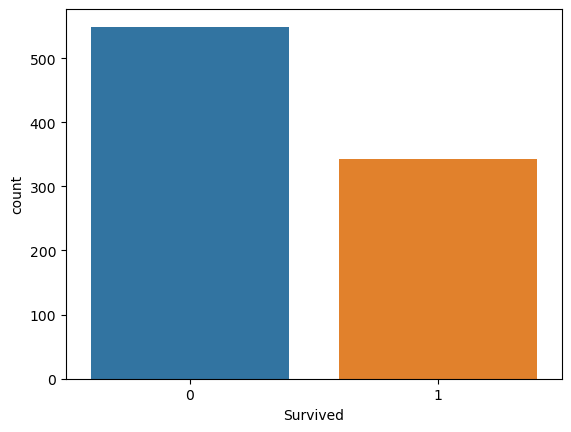
2. Pclass
# Pclass에 따른 인원 파악
titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).count()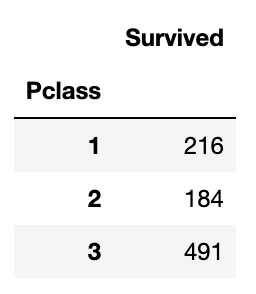
# 생존자 인원
titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).sum()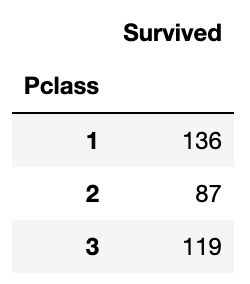
# 생존 비율
titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).mean()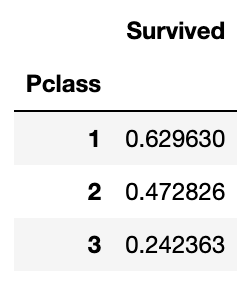
# 히트맵 활용
sns.heatmap(titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).mean())
plt.plot()
3. Sex
titanic_df.groupby(['Survived', 'Sex'])['Survived'].count()Survived Sex
0 female 81
male 468
1 female 233
male 109
Name: Survived, dtype: int64
# sns.catplot
sns.catplot(x='Sex', col='Survived', kind='count', data=titanic_df)
plt.show()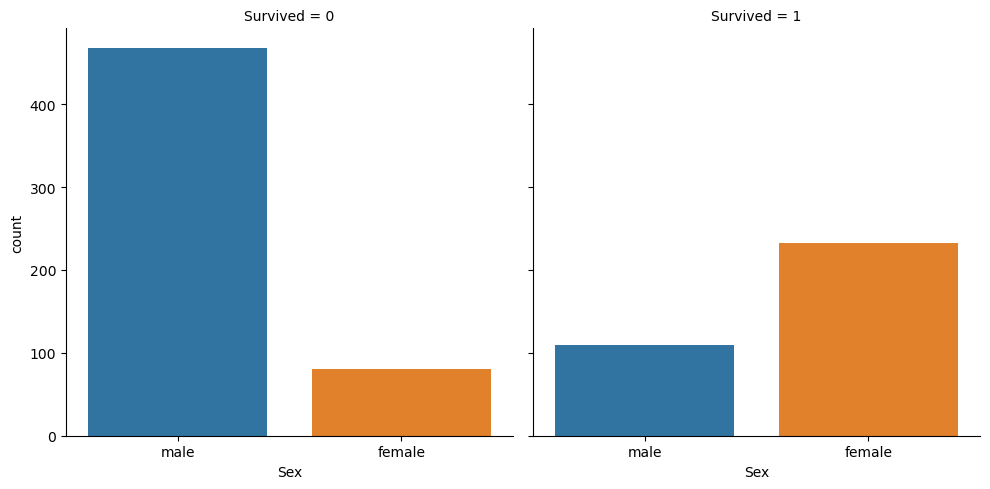
4. Age
Remind: 결측치 문제
titanic_df.describe()['Age']count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64
titanic_df[titanic_df.Survived == 1]['Age']1 38.0
2 26.0
3 35.0
8 27.0
9 14.0
...
875 15.0
879 56.0
880 25.0
887 19.0
889 26.0
Name: Age, Length: 342, dtype: float64
## Survived 1, 0과 Age의 경향성
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
sns.kdeplot(x=titanic_df[titanic_df.Survived == 1]['Age'], ax=ax)
sns.kdeplot(x=titanic_df[titanic_df.Survived == 0]['Age'], ax=ax)
plt.legend(['Survived', 'Dead'])
plt.show()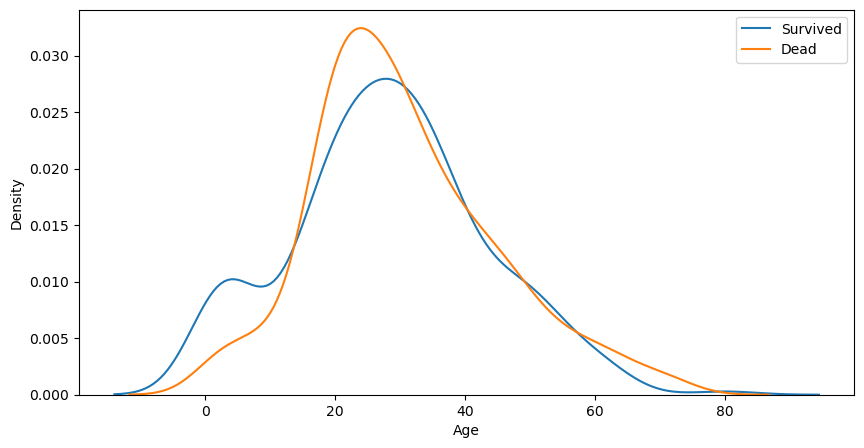
Sex + Pclass vs Survived
sns.catplot(x='Pclass', y='Survived', hue='Sex', kind='point', data=titanic_df)
plt.show()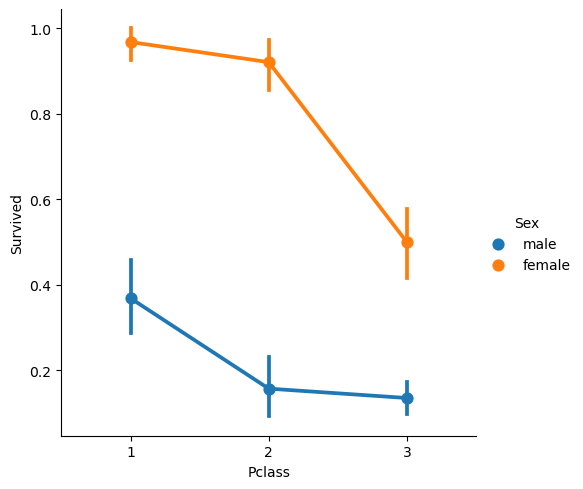
Age + Pclass
## Age graph with Pclass
titanic_df['Age'][titanic_df.Pclass == 1].plot(kind='kde')
titanic_df['Age'][titanic_df.Pclass == 2].plot(kind='kde')
titanic_df['Age'][titanic_df.Pclass == 3].plot(kind='kde')
plt.legend(['1st class', '2nd class', '3rd class'])
plt.show()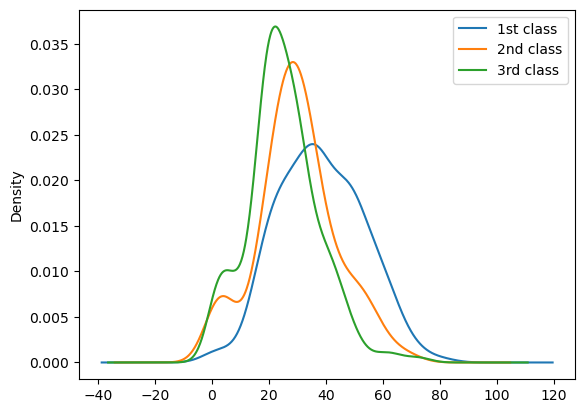
'BOOTCAMP > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
| [4주차 - Day5] 과제 (0) | 2023.04.19 |
|---|---|
| [4주차 - Day4] EDA Project 과제 (0) | 2023.04.08 |
| [4주차 - Day2] 클라우드를 활용한 머신러닝 모델 (0) | 2023.04.06 |
| [4주차 - Day1] Web Application with Flask (0) | 2023.04.05 |
| [3주차 - Day5] Python으로 시각화 프로젝트 (0) | 2023.04.01 |