2023. 6. 20. 19:00ㆍBOOTCAMP/프로그래머스 인공지능 데브코스

1. 데이터셋 다운로드(Colab)
# This mounts your Google Drive to the Colab VM.
from google.colab import drive
drive.mount('/content/drive')
# Enter the foldername in your Drive where you have saved the unzipped
# assignment folder, e.g. 'cs231n/assignments/assignment1/'
FOLDERNAME = 'cs231n/assignments/assignment1/'
assert FOLDERNAME is not None, "[!] Enter the foldername"
# Now that we've mounted your Drive, this ensures that
# the Python interpreter of the Colab VM can load
# python files from within it.
import sys
sys.path.append('/content/drive/My Drive/{}'.format(FOLDERNAME))
# This downloads the CIFAR-10 dataset to your Drive
# if it doesn't already exist.
%cd drive/My\ Drive/$FOLDERNAME/cs231n/datasets/
!bash get_datasets.sh
%cd /content/drive/My\ Drive/$FOLDERNAME코랩으로 해당 데이터셋을 다운로드하였는데요.CS231N Google Colab Assignment Workflow Tutorial 영상을 참고하여 진행해주시면 되겠습니다.
해당 실습은 'knn.ipynb' 파일에 있는 문제를 해결하는 과정이었습니다.
완성된 워크시트(워크시트 외부의 출력 및 지원 코드 포함)를 과제 제출과 함께 작성하는데요.
자세한 내용은 과정 웹 사이트의 과제 페이지를 참고하시면 됩니다.
kNN classifie는 두 단계로 구성됩니다.
교육 중에 분류자는 교육 데이터를 가져와서 단순히 기억합니다.
테스트 중 kNN은 모든 교육 이미지와 비교하고 가장 유사한 교육 예제의 레이블을 전송하여 모든 테스트 이미지를 분류합니다. k의 값은 교차 검증되며, 이 연습에서는 이러한 단계를 구현하고 기본 이미지 분류 파이프라인, 교차 검증을 이해하며 효율적이고, 벡터화된 코드 작성에 능숙합니다.
# Run some setup code for this notebook.
import random
import numpy as np
from cs231n.data_utils import load_CIFAR10
import matplotlib.pyplot as plt
# This is a bit of magic to make matplotlib figures appear inline in the notebook
# rather than in a new window.
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# Some more magic so that the notebook will reload external python modules;
# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2# Load the raw CIFAR-10 data.
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'
# Cleaning up variables to prevent loading data multiple times (which may cause memory issue)
try:
del X_train, y_train
del X_test, y_test
print('Clear previously loaded data.')
except:
pass
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# As a sanity check, we print out the size of the training and test data.
print('Training data shape: ', X_train.shape)
print('Training labels shape: ', y_train.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)Training data shape: (50000, 32, 32, 3)
Training labels shape: (50000,)
Test data shape: (10000, 32, 32, 3)
Test labels shape: (10000,)
# Visualize some examples from the dataset.
# We show a few examples of training images from each class.
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes)
samples_per_class = 7
for y, cls in enumerate(classes):
idxs = np.flatnonzero(y_train == y)
idxs = np.random.choice(idxs, samples_per_class, replace=False)
for i, idx in enumerate(idxs):
plt_idx = i * num_classes + y + 1
plt.subplot(samples_per_class, num_classes, plt_idx)
plt.imshow(X_train[idx].astype('uint8'))
plt.axis('off')
if i == 0:
plt.title(cls)
plt.show()

# Subsample the data for more efficient code execution in this exercise
num_training = 5000
mask = list(range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
num_test = 500
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
# Reshape the image data into rows
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0], -1))
print(X_train.shape, X_test.shape)(5000, 3072) (500, 3072)
from cs231n.classifiers import KNearestNeighbor
# Create a kNN classifier instance.
# Remember that training a kNN classifier is a noop:
# the Classifier simply remembers the data and does no further processing
classifier = KNearestNeighbor()
classifier.train(X_train, y_train)이제 kNN classifier로 테스트 데이터를 분류하려고 합니다.
이 프로세스는 두 단계로 나눌 수 있습니다.
먼저 모든 테스트 예제와 모든 열차 예제 사이의 거리를 계산해야 합니다.
이러한 거리가 주어지면 각 테스트 예제에서 가장 가까운 예제를 찾아 레이블에 투표하도록 합니다.
모든 교육 및 테스트 예제 사이의 거리 행렬 계산부터 시작하겠습니다.
예를 들어, Ntr 훈련 예제와 Nte 테스트 예제가 있는 경우, 이 단계에서는 각 요소(i, j)가 i번째 테스트와 j번째 기차 예제 사이의 거리인 Ntex Ntr 행렬이 되어야 합니다.
참고: 이 노트북에서 구현해야 하는 3가지 거리 계산의 경우 numpy에서 제공하는 np.linalg.norm() 함수를 사용할 수 없습니다.
먼저, cs231n/classifiers/k_nearest_neighbor.py를 열고 모든 (테스트, 기차) 예제 쌍에 대해 (매우 비효율적인) 이중 루프를 사용하고 거리 행렬을 한 번에 하나의 요소로 계산하는 compute_distance_two_loops 함수를 구현합니다.
# Open cs231n/classifiers/k_nearest_neighbor.py and implement
# compute_distances_two_loops.
# Test your implementation:
dists = classifier.compute_distances_two_loops(X_test)
print(dists.shape)(500, 5000)
# We can visualize the distance matrix: each row is a single test example and
# its distances to training examples
plt.imshow(dists, interpolation='none')
plt.show()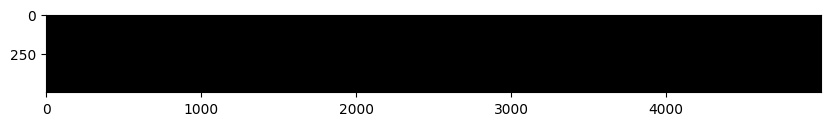
Q. 일부 행 또는 열이 더 밝게 보이는 거리 행렬의 구조화된 패턴에 주목합니다. 기본 색 구성표에서 검은색은 낮은 거리를 나타내고 흰색은 높은 거리를 나타냅니다.
1. 데이터에서 명확하게 밝은 행 뒤에 있는 원인은 무엇입니까?
2. 열의 원인은 무엇입니까?
A.
1. 거리 행렬에서 밝은 행은 테스트 이미지가 학습 이미지들과 거리가 멀다는 것을 나타냅니다. 이는 해당 테스트 이미지가 학습 이미지들과 비교했을 때 유니크하거나, 학습 데이터셋에 없는 새로운 특징을 가지고 있음을 의미할 수 있습니다.
2. 거리 행렬에서 밝은 열은 특정 학습 이미지가 모든 테스트 이미지들과 거리가 멀다는 것을 나타냅니다. 이는 해당 학습 이미지가 테스트 데이터셋의 이미지들과 비교했을 때 유니크하거나, 테스트 데이터셋에 없는 새로운 특징을 가지고 있음을 의미할 수 있습니다.
'BOOTCAMP > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
| [7주차 - Day2] ML_basics - Decision Theory & Linear Regression (0) | 2023.06.21 |
|---|---|
| [7주차-Day1] ML_basics - Probability (0) | 2023.06.21 |
| 보이스 피싱 AI 구별법(NLP) (1) | 2023.06.08 |
| [6주차 - Day4] ML_basics - Linear Algebra, Matrix Calculus (0) | 2023.05.14 |
| [6주차 - Day3] ML_basics - E2E (0) | 2023.05.14 |